Вторник, 31 Октября 2023
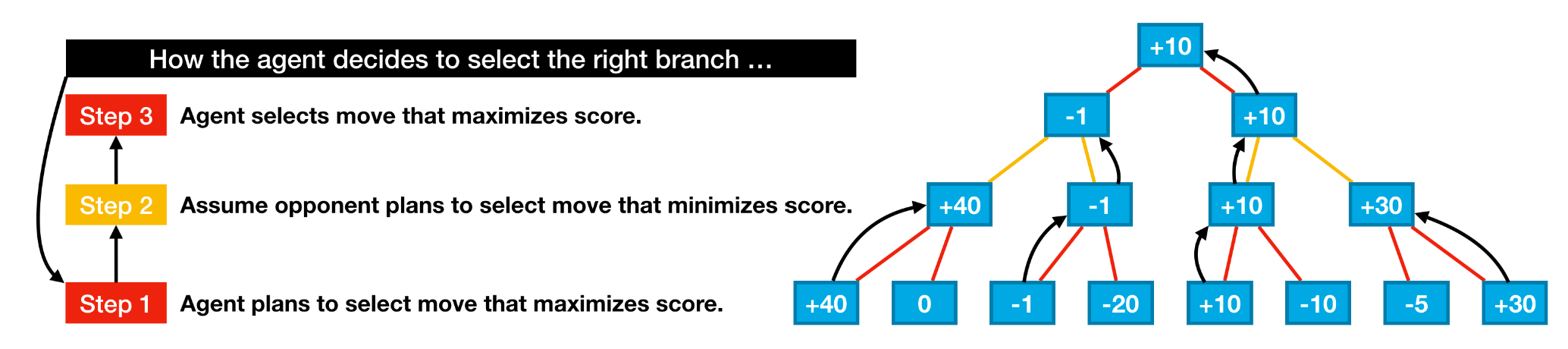
Изучил минимакс алгоритм. Смысл такой же как и в оне степ лук эхэд, только в данном случае мы просчитываем больше вариантов, смотря в глубину. Мы считаем что противник выберет наилучший для него ход, с наибольшим счетом, и в итоге выбираем наш ход, где например на глубине 3 ходя вперед мы будем в наилучшей позиции, а противник в наихудшей.
Код можно увидеть тут в Википедии
Начал изучать Deep Reinforcement learning