Понедельник, 15 Января 2024
Прошел курс по sql advanced на кагле
Join
Джоины это обединение таблиц по какому либо ключу. Самое лучшее обьединение это 1 к одному, но бывают обьединения один к многим или многие к многим.
Inner Join - соединяются только ряды где ключ есть в обоих таблицах
Right Join - все ряды из правой колонки и ряды где есть совпадающие ключи из левой
Full Join - все ряды из левой и правой колонки
SELECT name
FROM left_table as left
FULL JOIN right_table as right
ON left.id = right.left_id
может обьединятся не тольк опо айди, любая колонка подходит
Union
Юнион обьединяет ряды, добавляя в конец все ряды из второй таблицы
SELECT username FROM table1
UNION ALL
SELECT username FROM table2
UNION DISTINCT - можно использовать вместо юнион ол чтобы не включать дубликаты значений
Аналитические функции
Синтаксис
SELECT *,
AVG(time) OVER(
PARTITION BY id
ORDER BY date
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
) as average
FROM table1
Картинка обьясняющая как работает
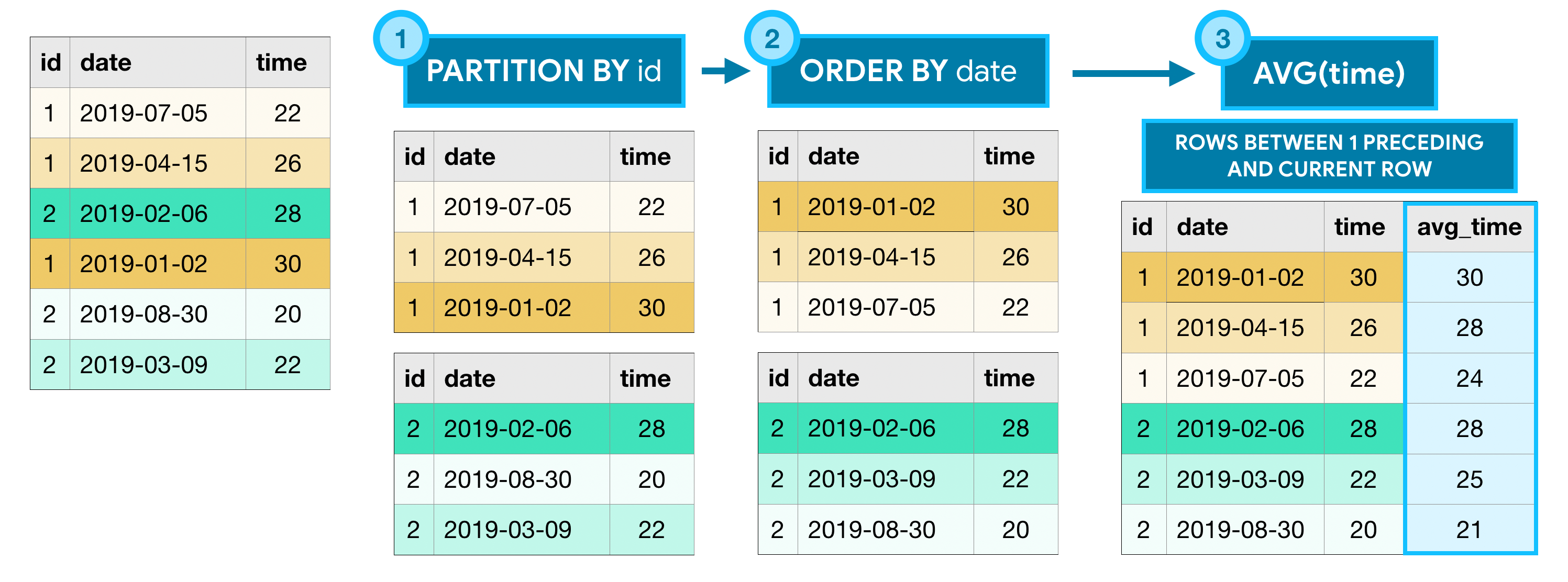
фреймы могут быть разными
- ROWS BETWEEN 1 PRECEDING AND CURRENT ROW
- ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING
- ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING - все ряды в партишене
Сами функции тоже разные бывают
Analytic aggregate functions
берут много инпут филдов и возвращают одно значение
- AVG()
- MIN()
- MAX()
- AVG()
- SUM()
- COUNT() - количество инпут рядов
Analytic navigation functions
не берут текущий ряд, а показывают один из партишена
- FIRST_VALUE()
- LAST_VALUE()
- LEAD() - следующий после текущего
- LAG() - предыдущий от текущего
Analytic numbering functions
даят какое либо число ряду в соответсвии с сортировкой
ROW_NUMBER() - начинается с единицы RANK() - Все ряды с одинаковым значением получают один ранк, в соответсвии с сортировкой, следующие значение получают ранк выше(добавляется число сколько было рядов в предыдущем ранке)
Вложенные и повторяющиеся значения
Ячейка в бигквери может содержать словарик с ключ-значением. Это вложенные значения
Вложенные
SELECT user.name
FROM table1
Ячейка также может содержать массив. Который в свою очередь может содержать словарик. Это повторяющиеся
Повторяющиеся
SELECT user.name, toy.name
FROM table1
UNNEST (toys) as toy
Пишем производительные запросы
Чтобы замерить качество производительности запроса, можно посмотреть на две метрики: количество просканированной информации и скорость выполнения запроса
from google.cloud import bigquery
from time import time
client = bigquery.Client()
def show_amount_of_data_scanned(query):
# dry_run lets us see how much data the query uses without running it
dry_run_config = bigquery.QueryJobConfig(dry_run=True)
query_job = client.query(query, job_config=dry_run_config)
print('Data processed: {} GB'.format(round(query_job.total_bytes_processed / 10**9, 3)))
def show_time_to_run(query):
time_config = bigquery.QueryJobConfig(use_query_cache=False)
start = time()
query_result = client.query(query, job_config=time_config).result()
end = time()
print('Time to run: {} seconds'.format(round(end-start, 3)))
на этом заканчиваю с sql и начинаю курс по тайм сириес